


3 Ways AI Leaders Can Benefit From Self-Learning Models
The engineering use cases of AI are widespread but often misunderstood. Companies misjudge the capabilities of AI and because of this, and therefore fail to see suitable applications of it in their workflows.
The reality is that AI is one of today’s fastest-growing technologies and can be used by engineers to build and analyse data without the need for data science expertise. For engineers, AI is game-changing, providing a low-cost means to stay competitive by cutting time-to-market, improving quality and efficiency, making faster decisions, and upskilling highly valuable R&D talent so they can work more independently and effectively.
Introduction to artificial intelligence
Implementing AI where it is not needed, however, can lead companies astray. AI is frequently used incorrectly due to biases in data and teams misunderstanding the very nature of these models.
A further, common misconception is that AI will replace skilled engineers and data scientists within a company, when it will rather instead be used by engineers as a tool to enhance and accelerate decision-making. After all, no one knows the data better than your engineers.
A Forrester report commissioned by Microsoft predicts a whopping 84% of technical decision-makers agree that their business has to go the data-driven route to maintain its competitive edge on the market. Artificial Intelligence (AI) is without a doubt a hot topic and will continue to play a critical role in businesses (see Figure 1).
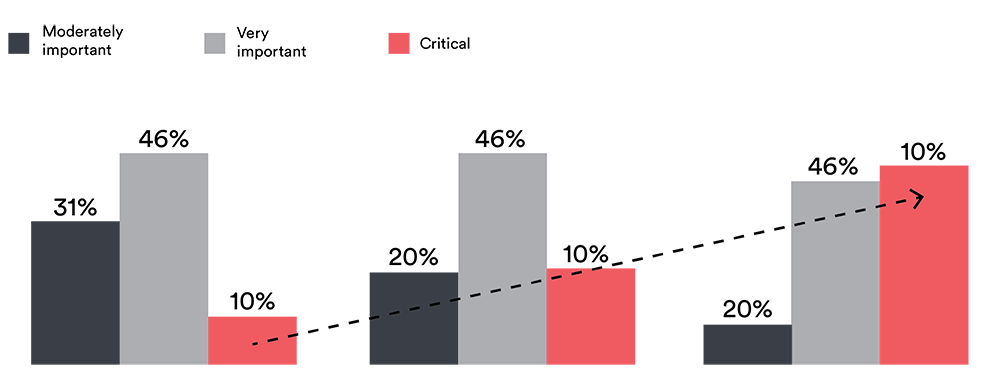
Figure 1: AI Is Critical To Long-Term Business Success. Base: 536 technical decision-makers responsible for AI implementations in US-based companies across various industries. (Source)
AI problems from unfit use cases and unsupervised learning algorithms
Another problem is that AI is being used by companies that have no business using it, and where its application does not have a solid business use case within the company for complex decision-making. Horror stories from these cases cause other technology companies that would benefit from AI to not adopt it.
An article in the Harvard Business Review said that some companies are waiting for self-learning AI technology to mature and for expertise in AI to become more widely available before adopting it, which may lead to shortfalls and a lack of competitive advantage in implementing AI and self-learning algorithms into their company systems.

Self-Learning AI models for engineers
Self-learning AI models train themselves using data and, once deployed, become better over time through a self-learning system. On a high level, these models recognise patterns (trained from supervised learning or unsupervised learning) in a dataset and draw meaningful conclusions, even when presented with different parameters or rare (unseen) scenarios in engineering use cases.
Ultimately, engineers in synergy with the self-learning model support each other to “fill in the blanks” through human input, and learn more about their intractable physical problems from self-learning AI.
However, self-learning AI does not work as straightforwardly as it seems. Statistically, around 51% of organisations simply do not have the right tools to make use of self-learning AI in their business setup (see Figure 2).

Figure 2: The three primary challenges leaders grapple with when building self-learning AI. (Source)
Teams of engineers are already able to design higher-quality products in a fraction of the time, and the data-driven approach allows the retention of knowledge for future generations of engineers. It also involves no iterative guessing game resulting in higher ROI, better quality products, and higher product performance in half the time.
By using this approach, the engineers of the BMW Group were able to use the wealth of their existing crash data using the Monolith AI platform to accurately predict the force on the driver’s tibia (more commonly known as the shinbone) for a range of different crash types through supervised learning for an ai system. This gave highly accurate results via self-learning algorithms, and completely removed the need for additional, costly, time-consuming physical tests. This is an exciting prospect and companies have shown interest in implementing self-learning algorithms and models into their organisations as quickly as possible to not lose touch with the digitisation of the industry, capitalize on their collective human intelligence, and stay ahead of their competitors.

There are a few things engineering companies can do to increase the chances of success of AI implementation and utilsing self-learning algorithms. This can help ensure that a company stays competitive by innovating and by still ensuring a positive ROI for the organisation.
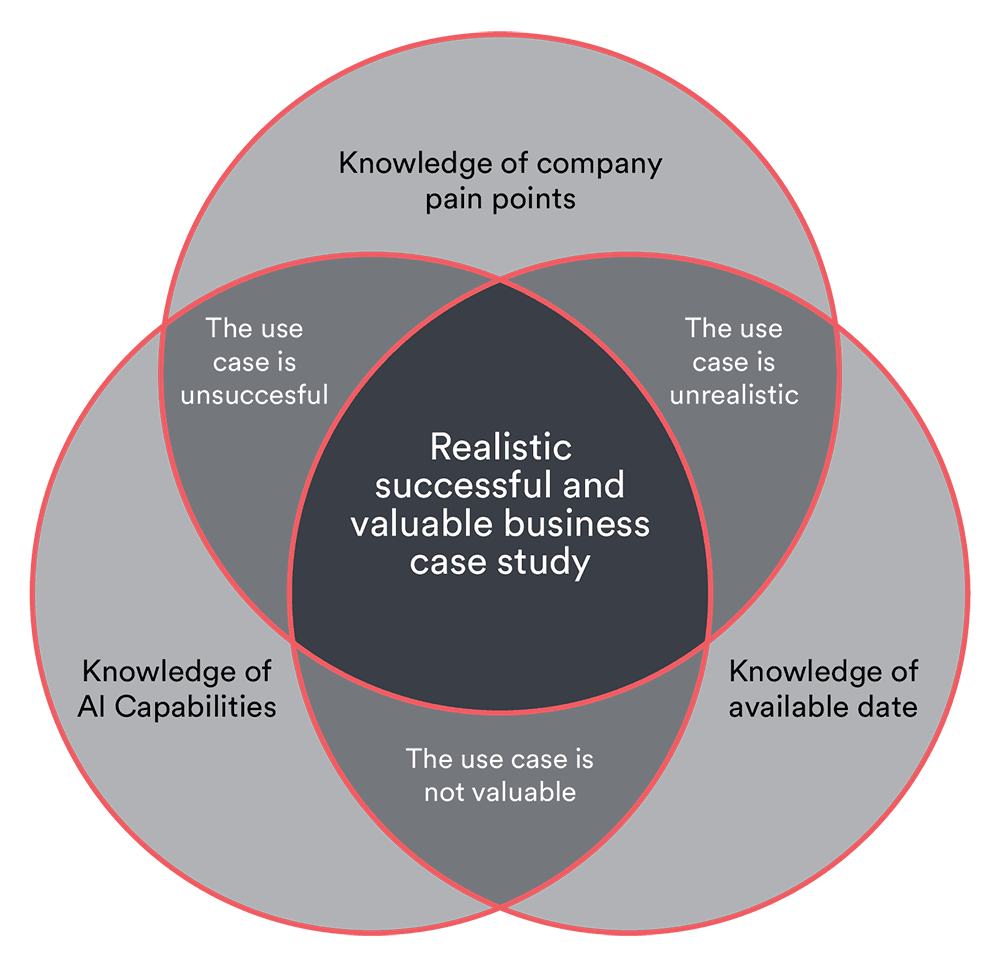
Figure 3: Only when knowledge of pain points, available data, and AI capabilities come together, a realistic and valuable business case study can be defined to achieve a positive ROI for a business.
1) Identify AI sweet spots
It’s tempting for companies to adopt technology in ‘hot’ industries like AI or machine learning (ML) for the sake of being on the popularity bandwagon but they are often unaware of whether self-learning AI will directly lead to a positive ROI. Some of these organisations fall victim to overusing AI and train models in every possible situation — even those where AI will not benefit them. This results in “AI Pilots” that may be technically interesting, but ultimately fail to be adopted beyond the Proof of Concept stage.. It is all well and good to adopt AI to predict results, but only if the results are useful or if the legacy workflow with analytical or physics-based models was not satisfactory in the first place.
For example, if physics-based methods such as Computational Fluid Dynamics (CFD) or Finite Element Analyses (FEA) can be run in a computationally light way, AI may not be needed to replace this process. However, in most cases where highly nonlinear, intractable physics is involved, simulations are very time-consuming, must be run multiple times, and are generally a costly road to pursue. AI is a prime candidate to help engineers in such use cases.
Self-learning models are ideal when simulations are too inaccurate or too slow, and when physical testing is expensive and time-consuming. We have seen the effects of having sufficient data points but slow simulations in our work with BMW, Honeywell or Kautex, who have since benefited from using self-learning models in their design process.
“For the development of a new gas metre, CFD models were not accurate enough to capture the complexity of the flow for varying temperature conditions and types of gases. Using Monolith, we were able to import our rich test stand data and apply machine learning models to conclude on different development options much faster.”
.png)
Bas Kastelein - Sr. Director Product Innovation (Honeywell Process Solutions)
Companies should therefore investigate and determine what parts of their business applications can leverage AI and how knowledge embedded in the data can be properly mined, without the risk of unnecessary expense, loss of productivity, and disrupting existing engineering workflows.
2) Know what AI is and what it can do
It is crucial for engineers to understand what AI can do and how to leverage its power. In our experience, people do not have a working knowledge of what machine learning is and, therefore, ask for unachievable outcomes. This wastes time and causes frustration.
AI is powerful, but it is not a magical all-encompassing solution to a company’s problems. Using the term “machine learning” reminds us that AI algorithms must learn before they can think. Understanding the basics of AI or, at least, its basic concepts can make a huge difference.
A single afternoon workshop with the Monolith experts could be enough to avoid common misunderstandings and give insights into the sorts of problems that AI can help solve. Looking at case studies from other departments or companies can also highlight the realistic applications of AI in your industry.
3) Know your data
Data is the lifeblood of AI algorithms. Many companies don’t know this, and often don’t understand their own data enough to know if AI will be useful. The accuracy of an AI model is dependent on the quality of the data and on how much data is available. The more complex the problem, the more data is needed. Some prospects have asked Monolith to predict results to an unrealistic accuracy criterion given the amount of data available.
The result: misalignment between customer expectations and AI model performance/accuracy.
The solution to this is to spend time understanding the data that is available. How many data points are available? In some cases, four points may be sufficient to give accurate results. In other cases, 4000 points may not be enough. Is the data highly complex or more categorically black-and-white? For example, determining if a component is manufacturable or not given certain parameters. Understanding the complexity of the problem is useful.
This can be measured according to the number of parameters needed or by the complexity of the relationship between inputs and outputs. Is it as simple as predicting the downforce on a vehicle given different chassis heights and body geometries? Or as difficult as using data from thousands of crash tests to predict the force on the tibia bone during multiple crash scenarios?
This will give an understanding of the amount of data required to get accurate and reliable results from AI models. Our AI experts support and advise our customers on every step of the data journey, from collection to cleaning, processing, modelling/training, evaluation, visualisation, and to integration. Don’t be shy, contact us to see what AI can achieve with your data!
“With Monolith’s machine learning method, we not only solved the challenge, we also reduced design iteration times and prototyping and testing costs. We are thrilled with the results, and we are confident we have found a way to improve future design solutions.”
.png)
Dr. Bernhardt Lüddecke - Global Director of Validation (Kautex-Textron)
AI is not magic, and it is not guaranteed to improve every problem that is thrown at it, but it can be an amazing tool to help predict trends in data and reach meaningful solutions - provided engineers understand the nature of their data and what is being fed into the model. Remember, no one knows your engineering data better than your engineers.
Conclusion: Implementing artificial intelligence and capitalising from machine learning algorithms
Companies who are successful in their use of AI, and there are many, have managed to reduce their time-to-market, increase their operational efficiency, and have joined the ranks of some of the most technologically-leading companies on the planet. To do this successfully, these companies understood that AI and ML are not the be-all-and-end-all solutions to their problems. What AI is and where its capabilities lie are defined in the context of their own problems. By using Monolith’s self-learning model capabilities, they get better insights into their data and build more performant and reliable products in a fraction of the time, knowing that AI can be a great solution for intractable physics problems.
The most valuable projects arise when your team of engineers understands their main pain points and the data they have gathered over the years. Educate them, introduce them to AI so that they understand its potential, and they will create realistic, successful, and valuable use cases to improve throughput, save time, stay competitive, and grow their technological capabilities.
